Pipeline Performance
Latency
Although CDL is logically an infinitely parallel system, processes cannot run until all of its input/output resources are available. Thus if a circuit contains a line of methods, this will form a sequential chain, that will have a 'longitudinal latency' (the time between events arriving at A and being ready at M), losing the benefits of parallelism. Thus it is beneficial to keep chains short.
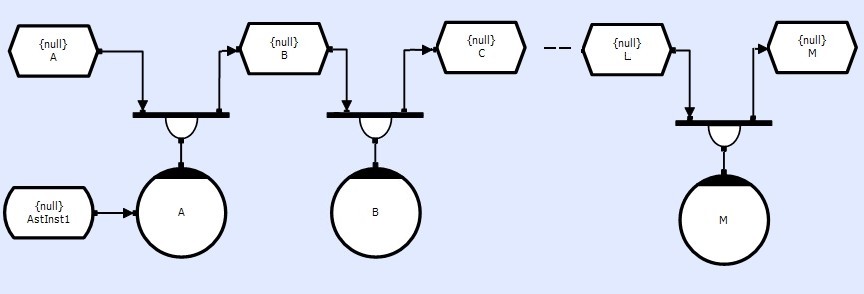
However, if the system can be driven fast enough (with suitable Buffer depth on the TST's), all methods can be keep busy (albeit on different data sets). Thus the system becomes an efficient 'pipelined system'. Although the longitudinal latency is still large, the frame-to-frame latency is small.
Bottleneck
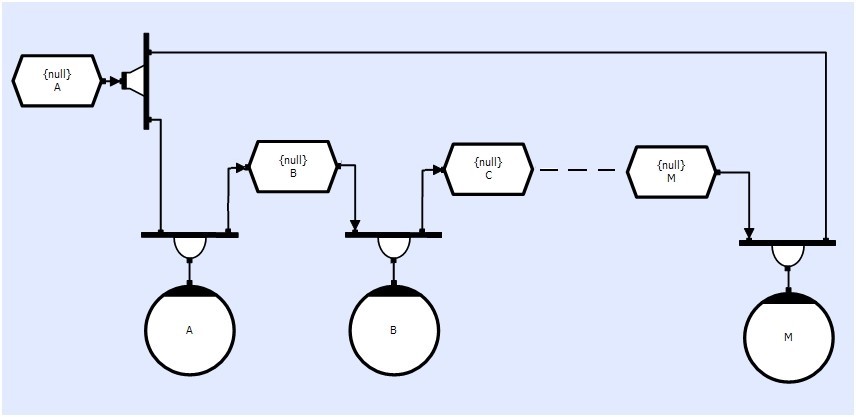
In this case TST A is distributed to both the start A and end M of the chain. If the buffer depth of A and or the reentrancy of the Dbx is 1 (or less than the number of processes in the chain) then methods A,B etc will not be able to operate on subsequent events until M has processed its copy of the event, and are thus being kept idle by TST A or the Dbx. Increasing the Buffer Depth of TST A AND the reentrancy of the Dbx to the length of the chain, will restore the pipeline.
Aborting
Overall system performance can be improved by only processing data that needs to be. In the Latency example above, Method A can make a judgement call on the data and decide that it is sub-standard. In which case it can abort the connection to TST B, effectively throwing the data/event any, and reducing the work that the rest of the chain has to do.
However, in the Bottleneck example TST A is distributed to A and M. If a where to dump its copy of the data/event, M would be left waiting for A's event to propagate through the chain.
If the Dbx had a reentrancy of 1 then the system would Deadlock. If it was higher then an event would eventually get to M but it would not be a matching pair. If the system was driven with a predefined number of events (eg.10 inputs) then there would be one left over in A, partly distributed.
Use Abort with care.
AST Performance
AST's have the largest overhead of any CDL object, due to its internal double buffering. Thus it is good practice to reduce the number of times that the store is accessed. Since its data is persistent, the likelihood is that it wouldnt have changed. For most AST's we can utilize the 'Notify' connection event to inform a method/thread that the data has changed, prompting the method/thread to go and read the data.
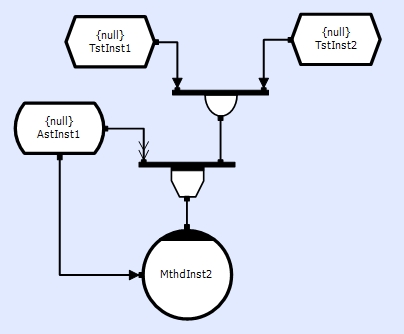 or
or 
In the first example above, the method will read the AST when it is ready to, however, the data it may have been updated again in between the notify and the read. This is not usually a problem (its an AST, if every change HAS TO BE processed use a TST). The Process code is made more complex as it needs to unpack an Aux connection.
In the second, the AST will be blocked until it has been read by the method, but the method is guaranteed to see every change of the data and the Process code doesnt need an Aux connection.
Transient Load
In all areas of the circuitry, the system can only perform at the speed of the slowest process. If this 'slowest' is dependent on the actual data or subject to external influence (eg. a tape recorder might arbitrarily decide to clean its tape heads), then the system can suffer from high transient loads. During these high load periods the remainder of the system is left idle.
By increasing the Buffer Depth of data stores, beyond the minimum required for the system to function, allows parts of the system to continue to function filling up the buffers. When the transient load is removed the rest of the system can catch up emptying the buffers.
As hardware/memory is ultimately limited, consideration needs to be given as to where the extra buffers are most useful.
Degradation
When a system cant keep up due to transient loads or there isn't enough processing power available, buffers will fill up and methods will block. Something, somewhere must give! Invariable this is at the input stage, as this is driving the system (but it could be elsewhere).
In the example below the Thread is reading data from a device and copying it to a data store. If the Thread blocked whilst trying to write to the store, the Thread would miss data arriving at the device. When the Thread resumed (when the system caught up) there would be jumps in the input data. As long as the processing chain was designed to cope with jumps everything would be fine. The system would just degrade for a while.
However, the hardware device may not be happy (this is often the case) and would be very likely to crash, bringing down the system. So rather than passively blocking on the store and see what happens, it is better to actively timeout on the write, and get back to reading the device. This prevents any system crash, and the Thread can raise a diagnostic to alert the user to the system degradation. The length of the timeout is dependent on the input rate and hardware etc.
Degrading in this way means the degradation is 'designed' into the system and a requirement placed on subsequent methods that they must cope with data jumps, rather than 'by luck' and 'hoping' developers 'guess' that they need to cope with data jumps.