Overview
Performance Issues come in a number of flavors
- Hardware
- Network
- Memory/Cache
- Software Bottlenecks
- Process Granularity
Hardware
No matter how clever or efficient the software, if the hardware can't process the data fast enough (100% loading) it never will. In this case the only solution is to port the application to hardware that can, whether this be a fast single-core, multi-core or distributed network. This leads to the other hardware issues, network and Memory/Cache.
Networks
In a Networked application data has to be transmitted over the network for processing and results returned to some central location. All networks are considerably slower than a processor's internal data bus, and their generic nature means that some form of scheduling or clash detection has to be implemented.
- Token Ring networks use time sliced data transfer windows
- Ethernet networks use free-for-all transmission, with clash detection
These impose further restrictions on the maximum network traffic that can be achieved (50% loading is a typical maximum throughput). Thus when designing networked applications data transfer should be minimised.
Although CLIP utilised a virtual network, hiding the actual network from the application, the CDL objects incorporate advanced features that help the CLIP Master decide whether to move data to processing or processing to data, or to move data directly between Slave processors rather than via the Master.
When writting a networked application read the descriptions of all of the objects attributes, many have subtle but powerful uses.
Method State/Workspace is another important area of potential overhead, when working with a networked application, developers need to have a clear understanding of the implications of each. In principle State data should be kept to a minimum (preferably 0).
Memory/Cache
In the early days of Personal Computers, program memory was severely limited (64KB on the Commadore 64) and programmers had to use all sorts of tricks. However, with the development of the 32bit processor and cheap memory, memory requirements took a back seat. Unfortunately as processors have got more powerful, user demands have got bigger (hence the need to multi-core and networked applications), however the 32bit processor has an absolute memory limit 4GB and operating systems reserve much of it for internal use (Microsoft Windows XP reserves 2GB and limits applications to 1GB).
This means that in this processor/memory hungry world, memory is again a issue and designers need to consider what data is stored, especially on a network where copies of the data may reside on several processors.
Another area of hardware development that has not kept up with processor speeds is memory access. This has been partly offset by the development of multi-level memory caches that hold recent/reusable data close to the processor core. However, when large amounts of data are being processed care should be used to minimise the number of cache misses (by processing memory locations sequentially, ie process arrays in order, not randomly).
Multi-core computers have 2 particular problems with memory and memory caches which is not highlighted in the literatures.
- Two-cores are supposed to go twice as fast as a single core, however, they have to compete for access to the memory via a data bus which is not running at twice the single core rate.
- Data used by a core is held in its local cache for fast reuse. However, if this data is also required by another core the operating system has to make sure that each cores cache is kept up to date. This is a considerable overhead if both cores are trying to access large common sections of the memory or both repeatedly update the same memory.
Many performance benchmarks have shown that 8-core machines can easily reduce to 4-core performance in these instances. Care needs to be used when designing algorithms for multi-core processing, to ensure each core accesses its own area of data and minimised its access to common areas of data.
Software Bottlenecks
Software bottlenecks occur whenever one or more processing chains are held up waiting for another chain to complete. This often happens when there is a chain that contains a single large slow process. Breaking this processing into smaller granules allows the process to be pipelined/parallelized and distributed over the processors/cores. Even if this does not allow the other tasks to run any sooner (relative time), it allows more processing to be utilised rather than left idle and will allow the other tasks to be run earlier (absolute time).
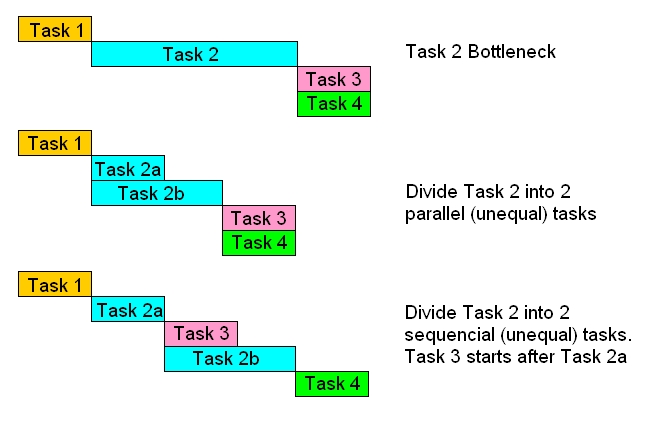
The section General Guidelines describes some of the other common bottleneck pitfalls and how to avoid them.
Process Granularity
Process granularity describes the size of each task that each process is to perform. In theory each add in an average calculation could be done by a separate process (with another for the final divide). However, the overhead of managing these processes becomes larger than the process itself.
There is no golden rule as to what is the smallest sensible process size, but a good guide is 'Each process should have a clear nameable purpose' eg. Average.
Some recursive algorithms, keep breaking the problem into smaller and smaller tasks until the problem can be solved, these types of algorithm need to define a clear cut off as to the smallest chunk that can be divided.
Eg. QuickSort
- Divide the data into lower and upper bands about some arbitary value (eg. the first in the unsorted data set).
- QuickSort each band.
This algorithm will recurse down until there is only 1 value in a band, which for large data sets with 2**n values will require n levels of recursion (ie 1,048,576 values will require 20 levels of recursion), with a significant overhead to just sort 2 numbers.
By trapping small bands (say, less than 513 values) and performing a traditional non-recursive slow sort saves up to 9 levels of recursion on each of the 2048 possible sub-bands.
The best cutoff size will be application/problem specific.
The CLIP documents 'Latent Task Concurrency' and 'Task Scheduling Latency', discuss in detail the performance issues relating to running parallel applications on multi-core hardware, with several benchmarks showing the relative performance of small/large grain processes. The reader is strongly urged to view these documents.