Overview
CDL circuitry describes logical program execution but does not make any assumptions about how that functionality will be mapped to individual processes. This means that applications can be distributed across any platform that has enough memory, processing bandwidth, communication bandwidth and other required resources. In particular it is usually possible to carry out most development and maintenance with a single process build, although it may not execute in absolute real time. SMP platforms typically only require a single process that scales to the number of cores that are discovered at runtime, but the more general case of a network of SMPs requires multiple processes to execute in parallel.
Intrinsic Concurrency
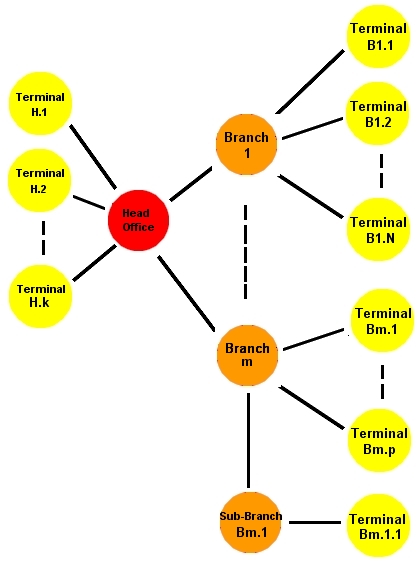
Applications are usually distributed for two different reasons. In the first case, they may have a natural sub-system architecture that needs to be physically distributed; this is referred to as 'intrinsic' concurrency. An example might be a banking application that has a central server sub-system at head office and a number of satellite terminals at branch level. In that case there would be at least two distinct executable process types; the server process and the terminal process. In this case there would probably only be one instance of the central server running at head office, but there might be hundreds of instances of the terminal process executing at branch level.
In this example, the whole logical application (server and terminals) therefore needs to be mapped to at least two process types, each of which will execute different parts of the overall circuitry. For most day to day development and maintenance purposes, it might be easier to work with a single process mapping that contains all of the functionality, and so in this case there would probably be at least two mappings required; one for day to day debugging etc, and one for release. The mapping operation involves identifying each required process, and then allocating a subset of the whole application's circuitry for each process to host.
Extrinsic Concurrency
The second reason for distributing applications is simply to achieve better performance; this is referred to as 'extrinsic' concurrency and in this case the application will probably have a natural sequential description that needs to be modified to realize potential parallelism.
Extrinsic concurrency can usually be addressed in two ways. Firstly it may be possible to further partition the functionality of intrinsic sub-systems into smaller functionally distinct sub-sub-systems, but a second and generally preferable approach is to use processing colonies as a means of distributing particular sub-systems.
Accretion
The mapping of application circuitry (logical) to executable processes (physical) is referred to as accretion (see Circuit Accretion). In this context, the term 'application' refers to the sum total of all circuitry, and this will be specified by the contents of the top level container circuit. Applications typically have multiple mappings from the top level container's contents to individual processes. Each one of these mappings is referred to as an 'Accretion'. Each Accretion will comprises a number of processes, with each process containing some part of the whole application.
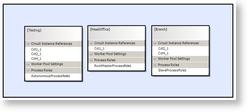
 Click to enlarge
Click to enlargeThe diagram above shows how the banking example could be accreted. The development accretion comprises a single process of type {Testing} which contains all of the circuitry. The release accretion comprises two processes, {HeadOffice} and {Branch}, each of which contain a sub-set of the whole application. The translator will create all three.
Processing Colonies
Processing colonies provide a second means of distributing application functionality. In this case a master process recruits one or more slave processes that share the master's workload.

In the example above, an intrinsic 'master' process dynamically recruits slave processes that share the whole processing load. The number of slave processes is generally unlimited and they can be recruited and retired at runtime without loss of application data. It is usually the case that the more slave process instances that are started, the faster the application will execute. This property is referred to as dynamic scale-ability and has a number of benefits over the sub-sub-system partition approach. Processing colonies are particularly applicable to data-parallel problems but can also provide very effective parallelization of more general irregular problems.
The runtime's dynamic scheduler generally achieves better load balance than can be achieved by functional partitioning. The separate master and slave executables result from linking the same application code with two distinct CLIP runtime variants and so there is only one process type to manage. Estimating CPU requirements is less critical because slaves can be added until the application achieves the required performance.
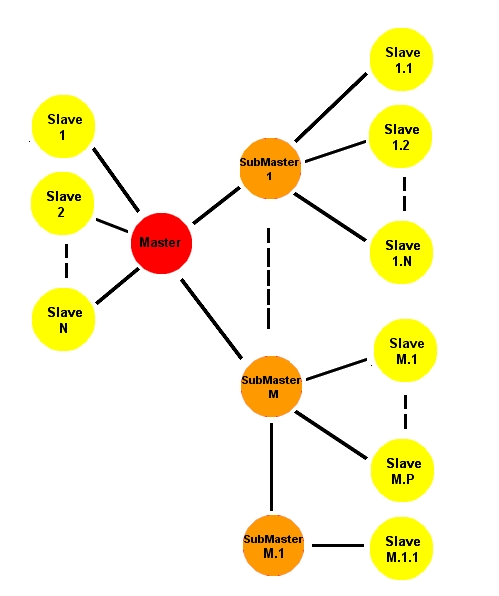
In the most general case applications can have a number of functionally distinct intrinsic sub-systems, each of which can be executed as a separate dynamically scale-able sub-master/slave colony. In the earlier banking example, the central server would probably run a root master build and a scalable number of slaves, each branch terminal could then execute as a separate sub-master which could also be 'slaved' (see above). Sub-masters can also recruit sub-sub-masters (see below).
The Main Thread
All CLIP processes have a 'main' thread that handles particular events that are generated by the user application threads. These include diagnostics, shutdown requests and other similar events, but more importantly, and if required, the main thread hosts the application's GUI.
The main thread starts up the application and then executes its message pump until the process exits. Drivers are required to deliver and retrieve events to and from the pump (see The Main Thread).
Process Structure
CLIP processes contain a number of components;
Infrastructure Code
Infrastructure code is generated from the circuitry that has been entered using the Blueprint editor. This code, along with any harness code that has been entered using the host IDE's text editor, will all be compiled into a single library.
Processing and Device Code
Processing and device code is just standard sequential code that is called from CDL's active objects and can be entered using any standard technique.
Tool Generated Code
CLIP applications are inter-operable with any other inter-operable code generating tools. The Microsoft Visual Studio development environment for example, can be used to generate the application's GUI code.
CLIP Runtime
CLIP processes must link with the appropriate CLIP runtime; Autonomous, Master, Sub-Master or Slave.
Third Party Libraries
Finally, any third party libraries can be linked with the application in the conventional way.
Process Initialization
At runtime, each process has to create, initialize and activate all the circuitry that it owns. This is performed by system and user generated harness code, and each process will be responsible for dealing with the particular circuitry that has been accreted to it. The particular actions that each process needs to perform will also depend upon their type; root-master, sub-master, slave, or autonomous. In general however, most of this code will be application specific rather than process specific.
Applications may however require code that is not strictly part of the application and an example would be code required to load runtime attributes (see Runtime Attribution). It could be that one or more object dimensions are determined at runtime and that some builds pass these from the command line, whilst others read from configuration files, flash memory and so on. Process initialization code is executed before any other user code and allows the system to be pre-configured using global access functions or some similar mechanism.
Process Attributes
CLIP processes have a number of configurable attributes that can be determined at translation time, build time and run time. See Process Attributes.